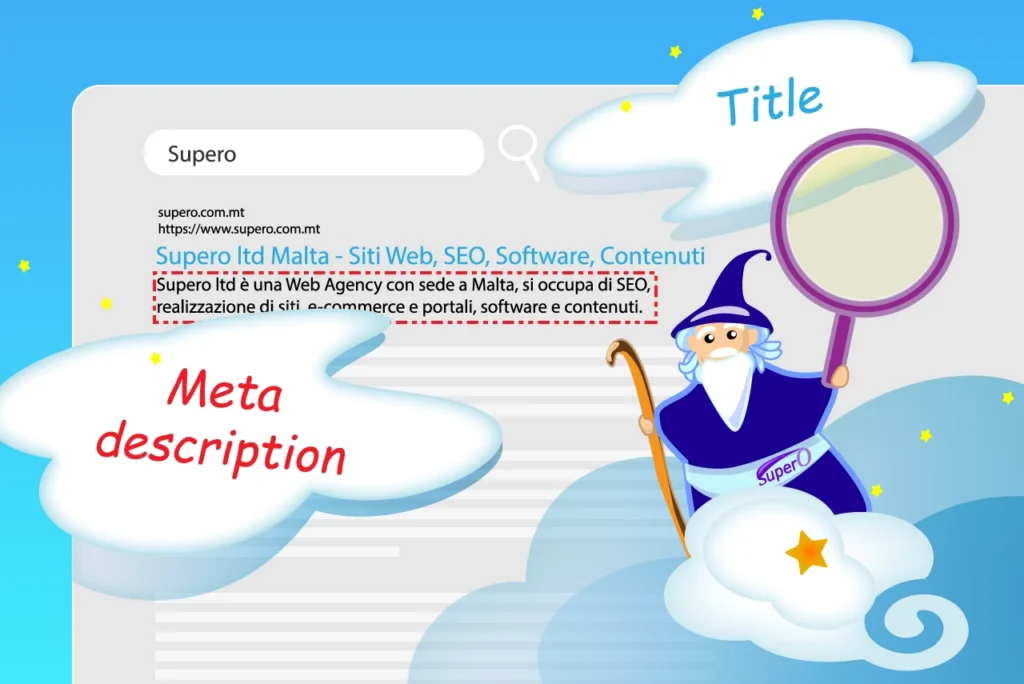
I tag meta robots
Usando correttamente i meta tag robots sulle pagine del sito è possibile istruire i motori di ricerca per indicare quali parti del sito vogliamo che siano lette o indicizzate. In questo articolo proviamo a vedere quali sono questi tag e che valori si possono usare, inoltre troverete un elenco che mostra quali motori di ricerca li supportano e quali no.
Va fatta una premessa importante: lo scopo di questi tag è di fornire un’indicazione ai motori di ricerca, non ha implicazioni legali, non crea un obbligo o un vincolo. In alcuni siti specializzati si dice che le istruzioni fornite tramite questi meta tag incentivano o disincentivano i motori di ricerca, non obbligano. Come vedremo ci sono dei casi in cui diversi motori di ricerca attribuiscono significati diversi allo stesso tag e anche casi in cui gli effetti dell’uso di un determinato tag non sono completamente chiari.
Concretamente quello di cui stiamo parlando è un tag contenuto all’interno del codice html, in particolare nella sezione <head>, non ha nessun impatto sulla visualizzazione della pagina. Per vedere il codice html di una qualsiasi pagina web basta usare la corrispondente funzionalità del browser, nella maggior parte dei casi basta premere Ctrl – U.
Come si presentano i meta tag robot?
Prima di esaminare la lista completa dei valori possibili proviamo a vedere qualche esempio a partire dai più semplici.
<!DOCTYPE html>
<html><head>
<meta name=”robots” content=”index, follow” />
(…)
</head>
<body>(…)</body>
</html>
La riga che ci interessa è quella evidenziata in grassetto, in questo esempio l’istruzione contiene due valori: il valore “robots” indica che l’istruzione è rivolta genericamente a tutti i crawler, i valori “index, follow” indicano che vogliamo che la pagina sia indicizzata e i link contenuti al suo interno siano seguiti.
Un esempio leggermente più complesso potrebbe essere:
<meta name=”googlebot” content=”noindex”>
<meta name=”yandex” content=”nosnippet”>
In questo caso stiamo chiedendo al bot di Google di non indicizzare la pagina, invece l’istruzione per il bot di Yandex è “nosnippet” che vedremo più avanti in questo articolo.
Quali sono gli user-agent?
Come abbiamo visto il meta tag è composto da due serie di valori, il primo contiene lo user agent, ovvero il destinatario dell’istruzione, il secondo valore contiene invece l’istruzione vera e propria. Quanti e quali sono gli user-agent che potrebbero interessarci? Centinaia, proviamo a vedere i principali:
- DuckDuckGo: il bot del motore di ricerca DuckDuckGo
- Baidu: lo spider di Baidu, motore di ricerca più usato in Cina
- Yandex: il bot di Yandex, motore di ricerca molto popolare in Russia
- Google: Googlebot
- Bing: Bingbot
In realtà le cose non così semplici perchè Google e Bing da soli, ad esempio hanno parecchi bot, ciascuno focalizzato su uno specifico servizio, ad esempio:
- Googlebot-Image
- Googlebot-News
- Googlebot-Video
- googleweblight
- AdIdxBot
- BingPreview
La lista completa dei bot di Google si trova qui mentre per Bing si può consultare questa pagina.
Quali valori si possono usare nel meta tag robots?
Eccoci arrivati all’elenco dei possibili valori del meta tag, questi possono essere inseriti uno alla volta oppure combinati insieme, inseriti uno dopo l’altro nell’attributo content (separati da una virgola).
index: permette al crawler di leggere la pagina e indicizzarla ovvero renderla disponibile al pubblico sul motore di ricerca. Questo è il valore di default quando non viene specificato niente.
noindex: indica ai motori di ricerca di non aggiungere la pagina all’indice, la pagina quindi non verrà mostrata tra i risultati delle ricerche del pubblico.
follow: indica al motore di ricerca che i link contenuti nella pagina possono essere seguiti.
nofollow: indica al motore di ricerca di non seguire i link contenuti nella pagina. Da notare che l’istruzione si riferisce a tutti i link della pagina, compresi quelli del menu, del footer, della sidebar eccetera. Va detto che l’esatto comportamento dei motori di ricerca in presenza di questa istruzione non è chiaro e non tutti i motori si comportano allo stesso modo, non si capisce se l’istruzione viene seguita alla lettera (il bot non segue i link) oppure se viene considerata un’istruzione che indica di non passare nessun valore alle pagine linkate.
none: questa è semplicemente l’abbreviazione per “noindex, nofollow”.
all: è l’abbreviazione per “index, follow”.
noimageindex: richiede di non indicizzare le immagini contenute nella pagina. Ovviamente si riferisce solo alle immagini ostate dal sito e non a quelle incluse ma ospitate su altri siti, va inoltre detto che se una stessa immagine è contenuta in un’altra pagina, priva di questo attributo, può essere indicizzata.
noarchive: chiede ai motori di ricerca di non fornire una copia cache della pagina.
nocache: significato identico a noarchive, usato in passato da MSN/Live.
nosnippet: chiede al motore di ricerca di non usare uno snippet testuale o video per presentare la pagina, quello che nei casi migliori coincide con il contenuto del tag description.
nositeindexsearchbox: chiede al motore di non mostrare la casella per la ricerca in linea.
nopagereadaloud: impedisce di usare i lettori vocali.
notranslate: chiede di non usare la traduzione della pagina nei risultati della ricerca.
max-snippet: indica il numero massimo di caratteri da usare nello snippet (description). Attenzione: se il valore viene omesso i motori lo interpreteranno come zero, se invece il parametro non viene indicato verrà usato il valore di defaul, cioè -1 che indica nessun limite alla lunghezza dello snippet.
max-video-preview: lunghezza massima (in secondi) dell’anteprima video da mostrare. Anche in questo caso se il valore viene lasciato vuoto viene interpretato come zero, se invece il parametro è completamente omesso il default è -1, cioè lunghezza illimitata (a discrezione del motore).
max-image-preview: serve a specificare la grandezza massima delle immagini da usare nell’anteprima, i valori accettati sono none, standard e large.
rating: indica che la pagina contiene contenuti per adulti.
unavailable_after: chiede che la pagina non venga mostrata nei risultati delle ricerche dopo una certa data. Il formato da usare è lo RFC850 (esempio: Monday, 15-Aug-05 15:52:01 UTC)
noyaka: chiede di non usare nello snippet la descrizione presente nella Yandex Directory. Ovviamente si applica solo a Yandex.
noodp: questa istruzione è obsoleta, la includiamo solo per… nostalgia e per il fatto che potreste incontrarla in alcune pagine piuttosto vecchie, indicava ai motori di ricerca (Google in particolare) di non usare nello snippet la descrizione presente nella (defunta) directory Dmoz.
Incoerenze e file robots.txt
Che succede se due valori sono in conflitto tra loro? Cosa succede se c’è incoerenza tra un valore specificato nel meta tag e un’istruzione fornita nel file robots.txt (abbiamo parlato estesamente di questo file qui).
La maggior parte dei motori di ricerca in caso di conflitto applica l’interpretazione più restrittiva, in altre parole nel dubbio tra “mostrare” o “non mostrare” una certa pagina i motori decidono di non mostrare. In ogni caso bisogna sempre fare attenzione ai possibili conflitti, per esempio le istruzioni fornite con un meta tag non possono essere prese in considerazione se la pagina è bloccata dal file robots.txt.
Approfondimenti
La maggior parte dei motori di ricerca pubblica informazioni dettagliate sull’uso del meta tag.